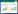 图 1 BERT-BiLSTM-CRF模型结构
Fig.1 BERT-BiLSTM-CRF model structure
图 1 BERT-BiLSTM-CRF模型结构
Fig.1 BERT-BiLSTM-CRF model structure
Liang Weizhong,Wang Shuhan,Wang Hongyu.Named entity recognition of magnesium alloy casting defects based on BERT pre-training model[J].Journal of Heilongjiang University of Science & Technology,2023,33(02):191-195.[doi:10.3969/j.issn.2095-7262.2023.02.008]

铸件在生产过程中往往会出现多种铸造缺陷,如气孔、缩孔和疏松等,这是困扰铸件生产相关企业的一大难题。通过长期研究积累了大量镁合金铸造缺陷相关的文本知识,在该领域开展命名实体识别研究,可以为镁合金铸造领域中铸造缺陷的诊断提供支撑,因此,选择一种相对完善的命名实体识别方法很有必要。
命名实体识别(Named entity recognition, NER)旨在识别出文本语言中的不同实体并将实体进行精准归类,被广泛应用于事件抽取、关系抽取、问答系统等方面。自MUC-6[1]被首次提出后,命名实体识别经历了从基于规则词典[2]、机器学习到基于深度学习的发展,对基于规则词典方法而言,规则的制定一般基于句法和语法的模式,难以迁移到别的领域,传统机器学习方法与前者相比,虽然可移植灵活性大大提高,但是仍然需要人工参与特征提取,近年来,随着计算机领域技术水平的提高,基于深度学习的命名实体识别方法得到了广泛应用。
Liu等[3]提出将BiLSTM-CRF模型融合人工设计特征应用于命名实体识别,在CoNLL2003数据集上取得88.83%的F1值。万里等[4]利用基于字词联合训练的BiLSTM命名实体识别方法,在中文电子病历数据集上的准确率达到98.28%。Lin等[5]针对地铁车载设备非结构化故障数据,提出多头自注意力机制和CNN-BiLSTM-CRF的命名实体识别,取得了较好效果。Huang等[6]利用双向LSTM与条件随机场(CRF)相结合进行判决文件命名实体识别,F1值达70.49%。Zhang等[7]提出了一种新的嵌入方法,将字符粒度和词粒度融合到文本编码,总体F1值在MSRA数据集上达到90.87%。上述方法虽在自然语言处理领域取得了一定成效,但都未能考虑上下文语境,存在着语言模型无法处理多义词表示的问题。Google实验室综合了不同语言模型的特点,提出BERT预训练模型,采用双向Transformer编码器,在预测下一个字时参考前后双向信息,有效解决文本信息表示的一词多义问题,实现了语义关系的提取。
目前,针对镁合金铸造领域,并没有专门的铸造缺陷语料数据集,笔者构建了镁合金铸造缺陷数据集,在提出的BERT-BiLSTM-CRF模型上进行验证,与当前主流的几个命名实体识别模型进行对比,以验证文中模型的有效性。
1 BERT-BiLSTM-CRF模型的构建文中提出的BERT-BiLSTM-CRF模型结构如图1所示。BERT-BiLSTM-CRF模型由BERT、双向LSTM和CRF三个模块构成。将“出现缩松缺陷”文本字符和标签输入BERT模块,利用Transformer编码器获取文本中每个字的输出向量,将输出结果输入BiLSTM层,进一步提取镁合金铸造缺陷不同实体的特征,CRF模块对全局进行正则化,以减少非法预测序列,保证正确识别出镁合金“缩松”缺陷名称实体。
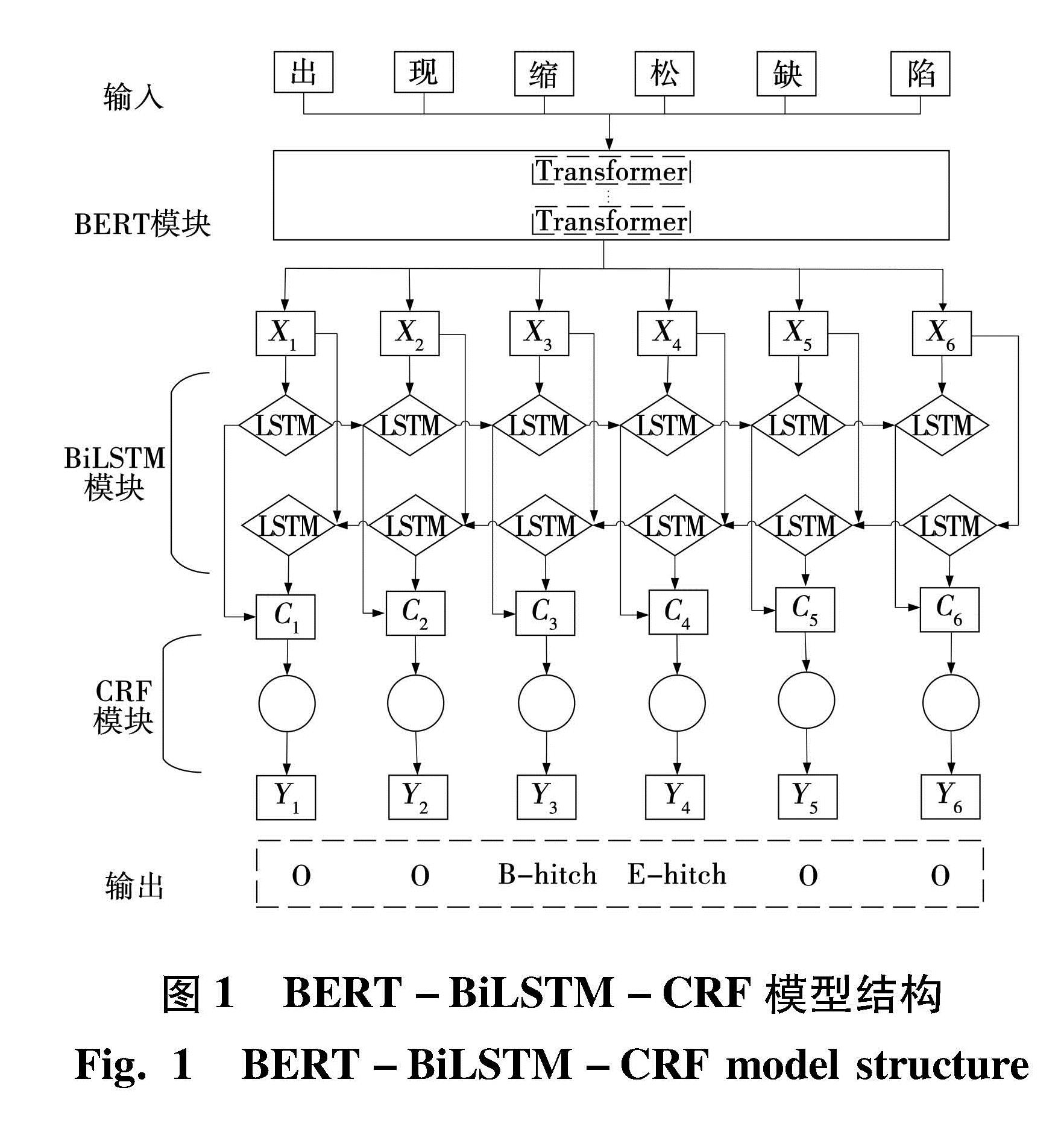
图1 BERT-BiLSTM-CRF模型结构
Fig.1 BERT-BiLSTM-CRF model structure
1.1 BERT预训练模型
在自然语言处理技术的发展中,Glove、word2vec等语言模型获取的是文本静态词向量,因而不能将词与词的上下文联系起来,导致多义词等语言现象不能得到处理。BERT[8]是从Transformer中衍生出来的预训练语言模型,如图2所示。其主要以两种方式来建立语言模型:遮罩语言模型(Masked language model,MLM)[9]任务,通过预测随机遮盖或替换的句子中的字词,模型可以从前后语境中领会文本的意义; 下一句预测(Next sentence prediction)任务,利用二项分类预测两个文本的相关性,判断两句话是否有上下文关系。通过这两个策略,BERT模型能解决文本在特征提取时出现的一词多义问题,使命名实体识别效果得到显著提升。
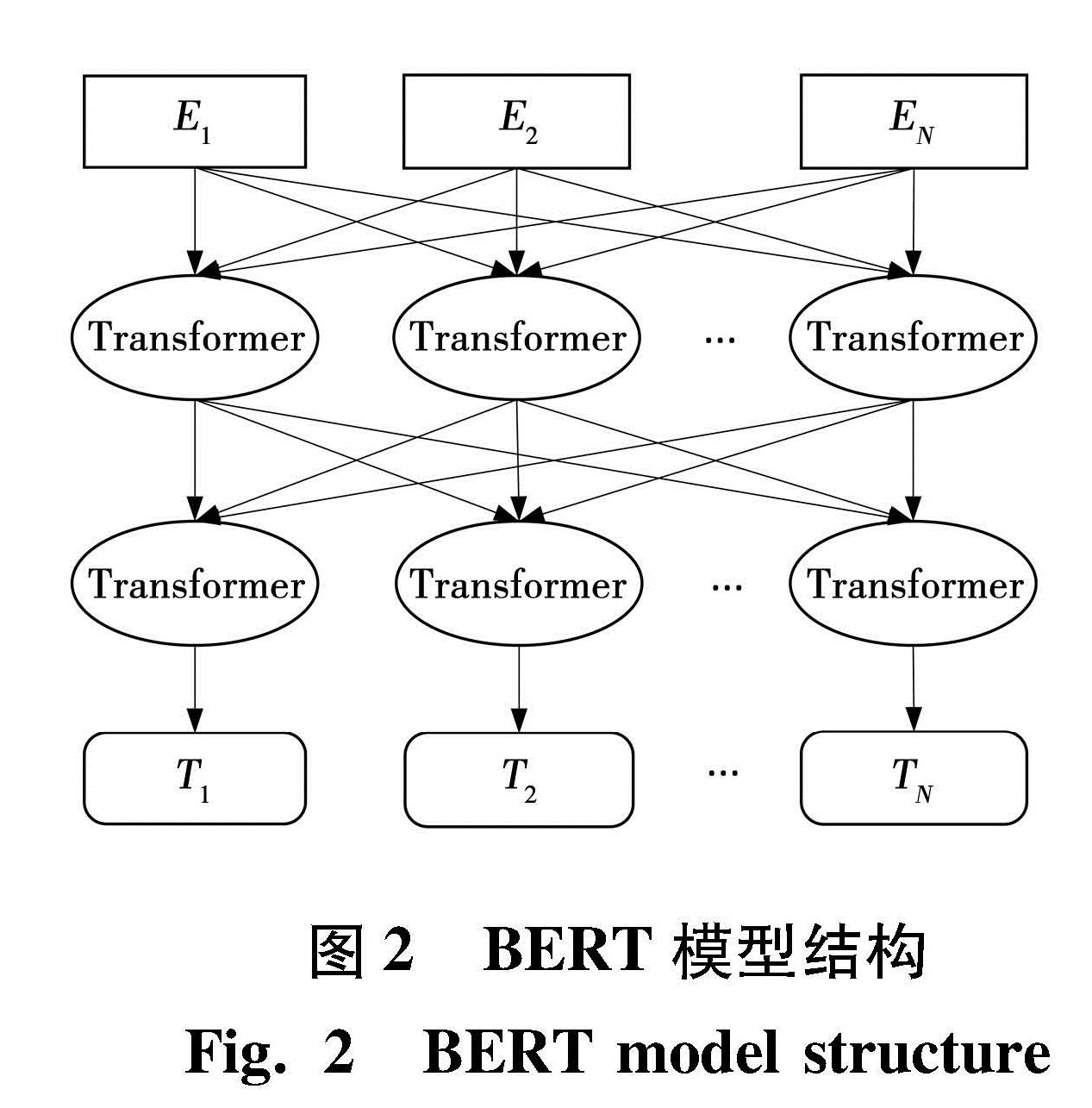
图2 BERT模型结构
Fig.2 BERT model structure
1.2 BiLSTM模块
1997年,Hochreiter[10]提出长短期记忆网络(LSTM),它是为解决训练时梯度爆炸问题的一种循环神经网络(RNN),LSTM引入“门”机制用以控制特征损失,其单元结构如图3所示。
图3 LSTM单元结构
Fig.3 LSTM unit structure
由图3可见,遗忘门用来选择丢弃哪些与铸造缺陷无用的信息,计算公式为
ft=σ(Wf[ht-1, xt]+bf)。
式中:σ——激活函数;
Wf——遗忘门的权重矩阵;
ht-1——上一时刻的隐藏状态;
bf——遗忘门的偏置向量。
输入门选择与当前铸造缺陷文本相关的信息进行输入,计算公式分别为
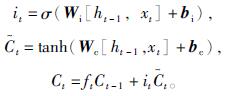
式中:Wi——输入门的权重矩阵;
bi——输入门的偏置向量;
Wc——细胞状态的权重矩阵;
bc——细胞状态的偏置向量;
Ct——时刻的单元状态;
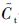 ——当前时刻的细胞状态。
——当前时刻的细胞状态。
输出门根据单元状态确定最后数据集的输出值,计算公式分别为
ot=σ(Wo[ht-1,xt]+bo),
ht=ottanh Ct,
式中:Wo——权重矩阵;
bo——偏置向量
由于LSTM从前向后编码,模型仅能获取文本单向的上下文信息,而BiLSTM包含前向LSTM和后向LSTM。它对镁合金铸造缺陷文本的每个字词序列采取前后双向LSTM,将同一时刻的LSTM进行融合,作为BiLSTM的输出,模型便可获取双向上下文信息。
1.3 CRF模块条件随机场(CRF)是一种无向图模型,它的输入是BiLSTM层输出的镁合金铸造缺陷语料中每个文本标签的分数,若没有CRF层,BiLSTM模块将每个字对应标签的最大概率作为预测输出。字词标签关系可能出现错误,CRF层通过学习镁合金铸造缺陷数据集中的特征设置约束规则,对标签序列起到约束作用,避免出现“I-type”在“E-type”之后的情况。
假设P为从上层输入的发射概率矩阵,T为转移概率矩阵,对于观测序列X=(x1,x2,…,xn),得到对应预测序列Y=(y1,y2,…,yn)的标签分数公式为
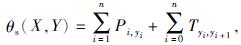
式中:Pi,yi——第i个字被标记成第yi个标签的分数;
yi——第i个预测序列值;
Tyi,yi+1——标签yi到标签yi+1的转移分数。
CRF层计算标签序列的条件概率公式为
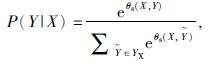
式中: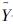 ——真实的标注序列;
——真实的标注序列;
Yx——所有可能的标注序列。
最终解码时利用维特比算法,公式为
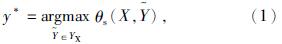
由式(1)可以获得,全局最优序列。
2 实验与结果分析2.1 数据集文中实验所用的语料数据集为自行收集的镁合金铸造缺陷知识语料,来源包括铸造缺陷手册、铸件生产技术文献等。对采集的文献进行数据清洗,删除图表等不可用部分,得到可用的文本154 652字。对语料进行分析后,确定了三种镁合金铸造缺陷实体类型,分别为铸造缺陷类别(type)、铸造缺陷名称(hitch)和铸造缺陷发生部位(position)。经统计,语料中各实体出现的频率为:铸造缺陷类别实体913个,铸造缺陷名称实体1 988个,铸造缺陷发生部位实体348个。
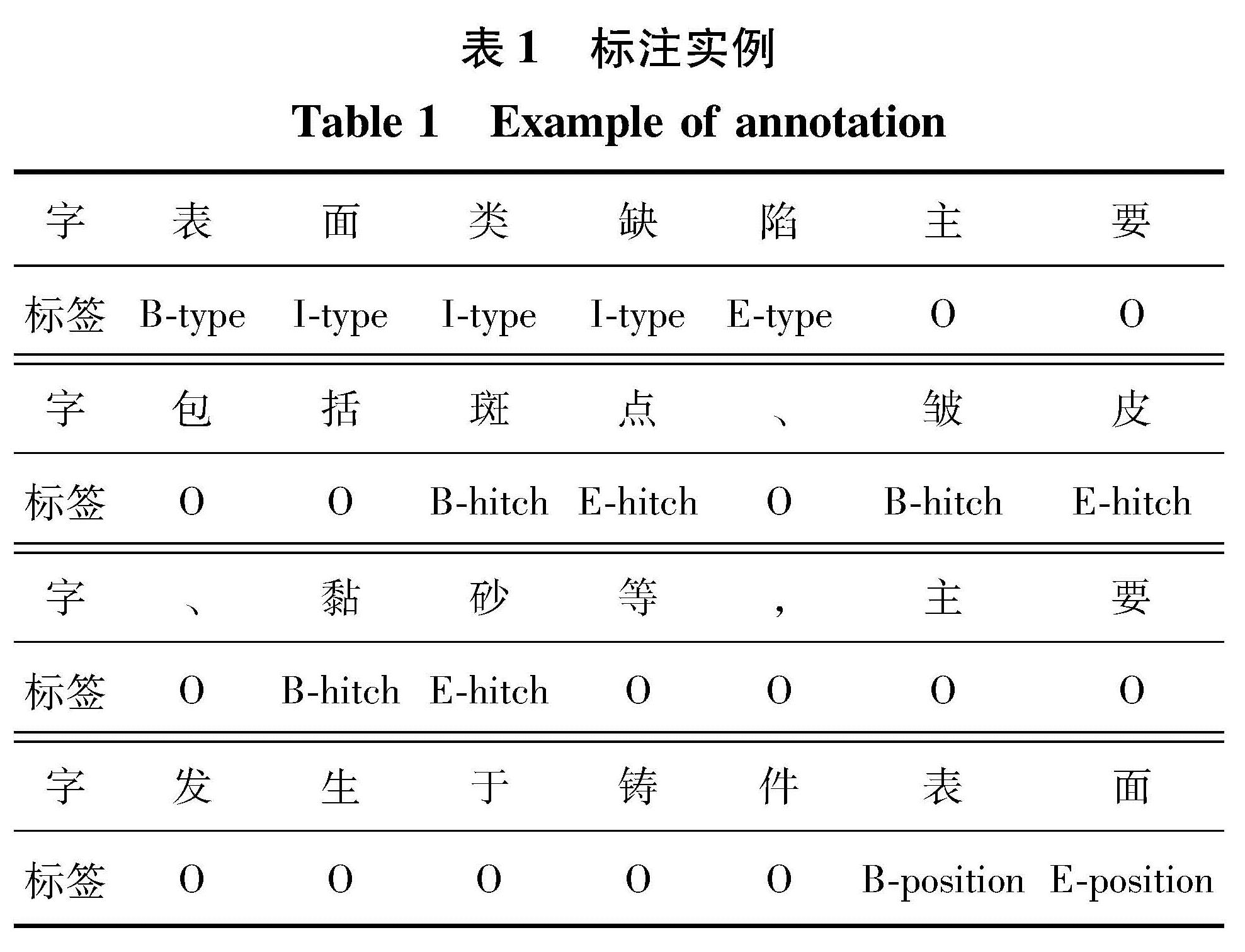
对于命名实体识别任务,数据集常见的标注方法有BIO、BIOES和BMES等,文中采用BIOES标注体系,实体的开始字符标注为B-x,实体的中间为I-x,实体尾部为E-x,O代表非实体部分,S表示改词本身为一个实体。体系共有十种标签,分别为“B-type”、“I-type”、“E-type”、“B-hitch”、“I-hitch”、“E-hitch”、“B-position”、“I-position”、“E-position”、“O”,表1为经程序data_process.py处理后数据集的标注实例。
根据实验要求,将自建镁合金铸造缺陷语料数据集划分为命名实体识别的训练集(train.txt)、验证集(dev.txt)和测试集(test.txt),三份数据集中文本数量之比大致为6:2:2。
表1 标注实例
Table 1 Example of annotation
2.2 评价指标
实验采用准确率(P)、召回率(R)和调和平均数(F1)作为验证模型对铸造缺陷实体识别效果的评价指标。准确率(P)指模型正确识别出的铸造缺陷实体数占识别出的铸造缺陷实体数的比例; 召回率(R)指模型正确识别出的铸造缺陷实体数占所有铸造缺陷实体数的比例; F1综合了准确率和召回率,其值越接近1表明模型效果越好,各个评价指标的计算公式为
P=(Tp)/(Tp+Fp),
R=(Tp)/(Tp+Fn),
F1=(2PR)/(P+R),
式中:Tp——正确识别出的铸造缺陷实体数;
Fp——错误识别出的铸造缺陷实体数;
Fn——未识别出的铸造缺陷实体数。
2.3 实验环境及参数设置文中实验采用PaddlePaddle框架进行模型的搭建,Python版本为3.7.9,CPU为AMD Ryzen 7 5800H,GPU为NVIDIA GeForce RTX 3060。
实验中模型采用Adam优化器,学习率设置为5×10-5,batch_size设置为16,max_len设置为128,epoch设置为10,dropout_rate设置为0.1。
2.4 实验过程读取镁合金铸造缺陷数据集,生成词典,将训练集、测试集及验证集中的数据转换为相应的格式,输送给BERT-BiLSTM-CRF模型。训练过程中,BERT-BiLSTM-CRF模型loss不断减小,经过9个epoch训练,模型loss便趋于0且不变,表明已完成模型训练。将训练好的模型文件保存在model文件夹下,待对模型进行测试验证。
2.5 实验结果为了验证文中提出的语言模型的有效性,用其他几个经典中文命名实体识别模型在自建数据集上的测试结果进行对比。IDCNN-CRF:模型采用迭代膨胀神经网络[11],运算效率高速度快。BiLSTM-CRF:使用双向LSTM 作为编码器,在命名实体识别方面应用甚广。数据基于自建镁合金铸造缺陷语料数据集,多次测试后结果如表2所示。预测结果如图4所示。
表2 不同命名实体识别模型测试结果
Table 2 Test results of different named entity recognition models
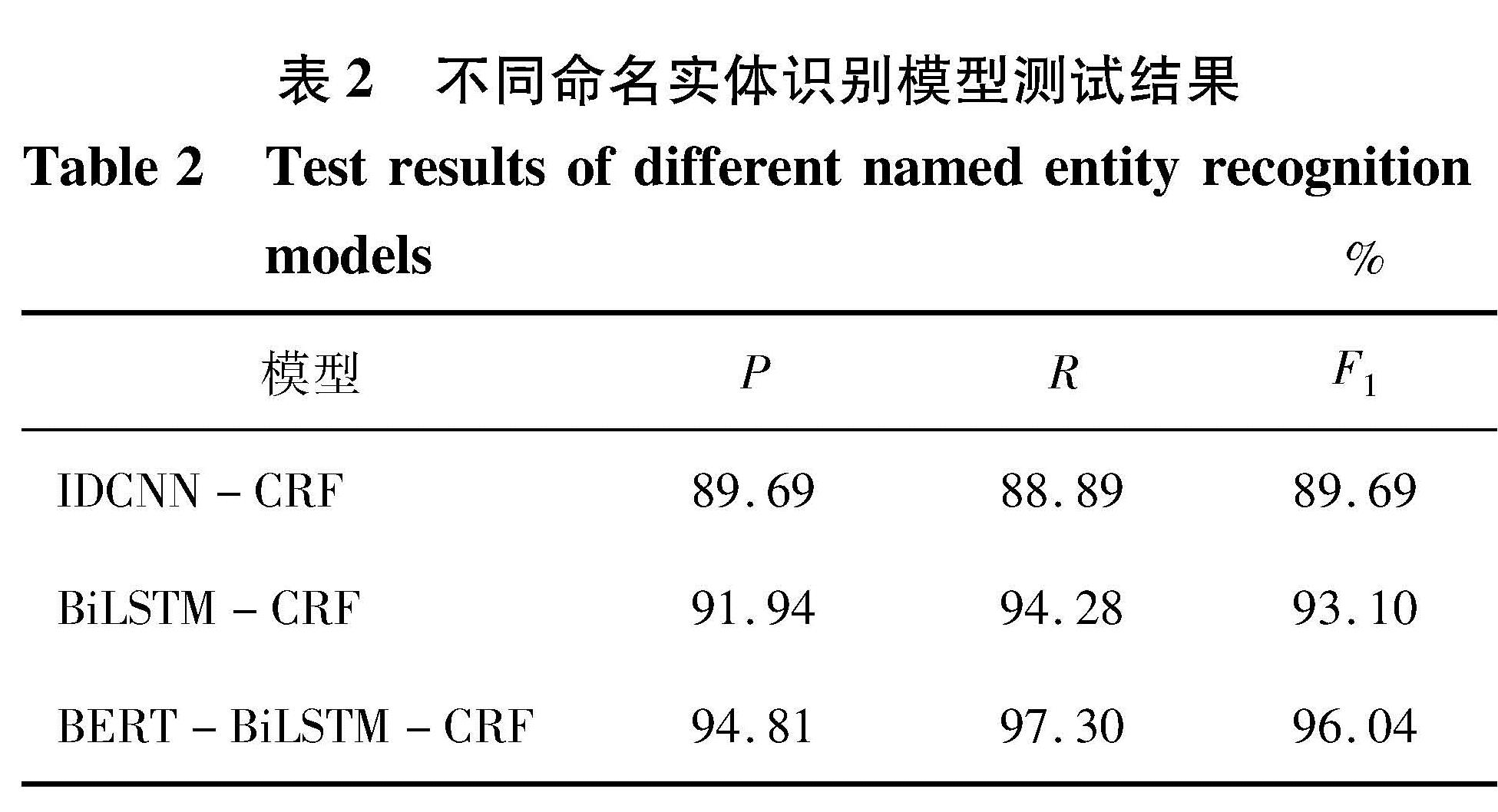

图4 镁合金铸造缺陷实体预测语料及结果
Fig.4 Prediction corpus and results of magnesium alloy casting defects
由表1可知,与验证的其他几个主流中文命名实体识别模型相比,BERT-BiLSTM-CRF模型在自建镁合金铸造缺陷语料数据集上的精确率、召回率和F1值取得的结果最好,将BERT预训练模型融入后,BiLSTM-CRF模型的精确率、召回率和F1值比原来模型分别提高了2.87%、3.02%和2.94%,表明BERT-BiLSTM-CRF模型具有更强的特征提取能力,在此数据集上命名实体识别效果更佳。经过测试,训练好的BERT-BiLSTM-CRF模型可以准确预测镁合金铸造缺陷各类实体。
3 结 论(1)针对镁合金铸造缺陷领域缺少专业语料数据集的情况,对手册、文献、书籍中铸造缺陷相关知识进行收集、数据清洗、分析,提取出铸造缺陷类别实体、铸造缺陷名称实体和铸造缺陷发生部位实体,研究镁合金铸造缺陷命名实体识别。
(2)构建了BERT-BiLSTM-CRF模型,使其更好地学习镁合金铸造缺陷相关字词结构特征和表征语义信息,通过在自建镁合金铸造缺陷语料数据集上的验证,与文中其他几个模型相比,BERT-BiLSTM-CRF模型的命名实体识别效果最好,F1值达96.04%,为后续镁合金铸造缺陷问答系统的研究提供基础。下一步还需继续完善铸造缺陷数据集,扩充数据量,使数据集中不同实体的数量更均衡。
- [1] Grishman R, Sundheim B. Message understanding conference-6:a brief history[C]. Proceedings of the 16th International Conference on Computational Linguistics, Association for Computational Linguistics, 1996: 466-471.
- [2] 廖列法, 谢树松. 基于注意力机制特征融合的中文命名实体识别[J]. 计算机工程, 2022, 21(1): 1-10.
- [3] Liu H S, Jun G, Zheng Y Y. Chinese named entity recognition model based on BERT[J]. Electronics, 2021, 12(1): 336-342.
- [4] 万 里, 罗曜儒, 李 智, 等. 基于字词联合训练的Bi-LSTM中文电子病历命名实体识别[J]. 中国数字医学, 2019, 14(2): 54-56.
- [5] Lin J, Liu E D. Research on named entity recognition method of metro on-board equipment based on multiheaded self-attention mechanism and CNN-BiLSTM-CRF[J]. Computational Intelligence and Neuroscience, 2022, 20(22): 478-483.
- [6] Huang W M, Hu D R, Deng Z R, et al. Named entity recognition for Chinese judgment documents based on BiLSTM and CRF[J]. EURASIP Journal on Image and Video Processing, 2020(1): 1-14.
- [7] Zhang N X, Li F, Xu G L, et al. Chinese NER using dynamic meta-embeddings.[J]. IEEE Access, 2019, 7: 245-251.
- [8] Yu Y Q, Wang Y Z, Mu J Q, et al. Chinese mineral named entity recognition based on BERT model[J]. Expert Systems With Applications, 2022, 206: 796-804.
- [9] Vo T. SynSeq4ED: a novel event-aware text representation learning for event detection[J]. Neural processing letters, 2022(1): 54-60.
- [10] Hochreiter S, Schmidhuber J. Long short-term memory[J]. Neural Computation, 1997, 9(8): 1735-1780.
- [11] 杨美芳, 杨 波. 基于笔画ELMo嵌入IDCNN-CRF模型的企业风险领域实体抽取研究[J]. 数据分析与知识发现, 2022, 6(9): 86-99.